A Beginner's Guide to Bayes' Theorem, Naive Bayes Classifiers and Bayesian Networks
Bayes’ Theorem is formula that converts human belief, based on evidence, into predictions. It was conceived by the Reverend Thomas Bayes, an 18th-century British statistician who sought to explain how humans make predictions based on their changing beliefs. To understand his theorem, let’s learn its notation.
Bayesian Notation
Here’s how to read Bayesian notation:
-
P(A)means “the probability that A is true.” -
P(A|B)means “the probability that A is true given that B is true.”
In this case, it’s easiest to think of B as the symptom and A as the disease; i.e. B is a skin rash that includes tiny white spots, and A is the probability of the measles. So we use phenomena or evidence that is easily visible to calculate the probability of phenomena that are hidden. What you can see enables you to predict what you can’t see.
It turns out that the the probabilities of A and B are related to each other in the following manner:
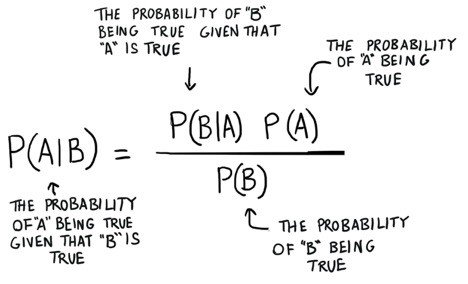
That is Bayes Theorem: that you can use the probability of one thing to predict the probability of another thing. But Bayes Theorem is not a static thing. It’s a machine that you crank to make better and better predictions as new evidence surfaces.
| An interesting exercise is to twiddle the variables by assigning different speculative values to P(B) or P(A) and consider their logical impact on P(A | B). |
For example, if you increase the denominator P(B) on the right, then P(A|B) goes down. Concrete example: A runny nose is a symptom of the measles, but runny noses are far more common than skin rashes with tiny white spots. That is, if you choose P(B) where B is a runny nose, then the frequency of runny noses in the general population decreases the chance that runny nose is a sign of measles. The probability of a measles diagnosis goes down with regard to symptoms that become increasingly common; those symptoms are not strong indicators.
Likewise, as measles become more common and P(A) goes up in the numerator on the right, P(A|B) goes up necessarily, because the measles are just generally more likely regardless of the symptom that you consider.
Naive Bayes Classifiers: A Playful Example
Maybe you’ve played a party game called Werewolf.1
It’s what they call a “hidden role” game, because roles are assigned to you and your fellow players, but nobody knows what anyone else is.2 You take a group of, say, 10 players and divide them into two roles – werewolves and villagers. Everyone draws slips of paper from a hat, closes their eyes, and then the werewolves are instructed to wake up to know who’s on the werewolf team.
Since only the werewolves know that they are werewolves, everyone in the game claims to be a villager. As the game moves through artificial cycles of day and night, each night the werewolves wake up and kill one villager, and each day the villagers try to figure out who the werewolves are, and vote to lynch one player based on their suspicians. Good, clean fun!
So a great way to learn Bayes Theorem, and in particular the implementation called Naive Bayes, is to think about how you track down a werewolf. So A is the variable you are trying to predict: It is a categorical variable that can be either A1 == werewolf or A2 == villager. Your job in this game is to act as a binomial classifier. B would be all the symptoms of werewolfiness, which in this case mean the symptoms of deception, since the werewolves only win by hiding their identity from the villagers as they slowly kill those poor people off.
The moderator of the game tells you how many werewolves there are, that’s P(A1), but doesn’t tell you who.
Over the course of your life, you’ve learned that people do certain things when they’re nervous, lying to you and afraid of getting caught.
So you start looking for symptoms you might use to diagnose a werewolf: Are they shifting in their seat? p(B1=Shifting|A1) Are they avoiding eye contact? p(B2=AvoidEyeContact|A1) Are they touching their face or hair with their fingers? p(B3=ActiveFingers|A1) That is, instead of using the symptoms to diagnose the disease P(Measles|Rash), you’re flipping it around, using an assumed diagnosis to predict the probability of symptoms. This is the generative side of Bayes.
What is the probability that you exhibit a combination of these symptoms if you are a werewolf? It’s P(B1, B2, B3 | A1).
And so your prediction that someone is a werewolf or a villager would be: Prediction = argmax_A[P(B1, B2, B3| A) * P(A)] for all A.
At the end of each round, when a person is lynched, you find out whether they were, in fact, a werewolf or a villager.
(For our purposes, that means you can update what you know about P(A1), or the probability that one of the remaining players is a werewolf.) And that, in a microcosm, is the magic of Bayes, allowing you to incorporate new knowledge about the world into this machine that updates your beliefs.
The only problem is that, as the number of features you analyze increases (i.e. B grows larger), P(B1, B2, B3,
B4 | A) gets very hard to compute without a large sample. You would have to see each, exact combination of features many times to calculate their probilities. That’s where the “naive” part of Naive Bayes comes in: Naive Bayes assumes all inputs are conditionally independent.
Instead of trying to find the probability of B1, B2, B3 etc. occurring simultaneously for a certain label, you calculate the probability of each feature occurring individually given that label: P(B1, B2, B3, B4| A1) = P(B1|A1) * P(B2|A1) * P(B3|A1) * P(B4|A1)
We assume their combinations don’t matter. Each symptom has a relationship with the probability of werewolf, but combinations of those symptoms do not increase that probability. Why do we call that assumption “naive”?
The features avoiding eye contact and usually friendly on their own might not tell you a lot about whether the person in question is a werewolf. P(B1|A1) * P(B2|A1)
But if you know simultaneously that a person who is usually friendly has suddenly fallen quiet and is avoiding all eye contact, common sense dictates that your expectation of that person being a werewolf should increase. P(B1, B2|A1).
So Naive Bayes discards information in favor of computational efficiency, a tradeoff we’re forced to make with other algorithms like convolutional networks as well.
Bayesian Networks
Bayesian networks are graphical models that use Bayesian inference to compute probability. They model conditional dependence and causation. In a Baysian Network, each edge represents a conditional dependency, while each node is a unique variable (an event or condition). Bayesian networks were invented by Judea Pearl in 1985. They were a particularly popular approach to machine learning problems in the 1990s, and remain a powerful tool for thinking about causality.
Bayesian Network can be used to model any number of causal relationships. Instead of tackling werewolves and the symptoms of deceipt, you could try to model all the possible causes of your front lawn being wet, which would include rain and sprinklers and leaky fire hydrants and kids with squirt guns (this scenario is, in fact, the hello world of Bayesian Networks).
Bayes’ Theorem in (Kind of) Popular Culture: Rationalism
Bayes’ Theorem is a central tenet of a group called the Rationalists, a global community with many members in the San Francisco Bay Area, which organized itself for years around the blog LessWrong. The Rationalists are likely the largest community to prioritize AI alignment and AI safety.
Rationalists employ the language of Bayesianism to describe their efforts to move beyond their own cognitive biases and update their beliefs.3 Thus, a statistical term of art also acts as a profession of group belonging.
Eliezer Yudkowsky is perhaps the most well-known rationalist, and a leader of the group. While Yudkowsky’s writings are prolific, the creation texts around which he organized much early rationalist discussion are called the Sequences.
Yudkowsky issued early warnings about the dangers of superintelligence and hostile AI. By creating a space for the discussion of artificial general intelligence (AGI), his writings and thought paved the way for later AI research organizations such as DeepMind and OpenAI, which themselves are responsible for many AI breakthroughs in recent years.
Organizations focused on AI safety, such as the Future of Life Institute and the Future of Humanity Institute, can also be interpreted as stemming from the same movement. Elon Musk emerged as a prominent advocate of AI safety, co-founding OpenAI and later Neuralink, which seeks to fuse AI with humans. If you can’t beat’em, join’em.
Yudkowsky is now a research fellow at the Machine Intelligence Research Institute, and for years sponsored the Singularity Summit, an annual event that brought together the people thinking about strong AI before it was cool. The last summit took place in 2012.
Further Reading (To Causality, and Beyond…)
- Interactive Graphic: Conditional Probability
- Judea Pearl: Bayesianism and causality, or, why I am only a half-Bayesian
- Judea Pearl’s home page
- Causality: Models, Reasoning and Inference
- Counterfactuals and Their Applications
- Probability Theory: The Logic of Science Reading Course Introduction (Aubrey Clayton)
Footnotes
1) Thanks to Andy Seow for this scenario.
2) It’s interesting to consider that medical doctors are forced to play a “hidden role” game with disease, which doesn’t announce itself by name but only indirectly by symptoms. And indeed, most of the most important things that happen in the world don’t happen when you’re there, but rather in your absence, distant in space and time, and you are left to diagnose them by their visible repercussions.
3) And in the machine learning community, parametric models are “updated” each time their parameters are corrected to more accurately approximate an objective. In the case of “deep belief networks”, an early deep learning model pioneered by Geoff Hinton and his team, the link to Bayesian language is explicit.”

Chris V. Nicholson
Chris V. Nicholson is a venture partner at Page One Ventures. He previously led Pathmind and Skymind. In a prior life, Chris spent a decade reporting on tech and finance for The New York Times, Businessweek and Bloomberg, among others.