A Beginner's Guide to Multilayer Perceptrons (MLP)
Contents
- A Brief History of Perceptrons
- Multilayer Perceptrons
- Just Show Me the Code
- FootNotes
- Further Reading
A Brief History of Perceptrons
The perceptron, that neural network whose name evokes how the future looked from the perspective of the 1950s, is a simple algorithm intended to perform binary classification; i.e. it predicts whether input belongs to a certain category of interest or not: fraud or not_fraud, cat or not_cat.
The perceptron holds a special place in the history of neural networks and artificial intelligence, because the initial hype about its performance led to a rebuttal by Minsky and Papert, and wider spread backlash that cast a pall on neural network research for decades, a neural net winter that wholly thawed only with Geoff Hinton’s research in the 2000s, the results of which have since swept the machine-learning community.
Frank Rosenblatt, godfather of the perceptron, popularized it as a device rather than an algorithm. The perceptron first entered the world as hardware.1 Rosenblatt, a psychologist who studied and later lectured at Cornell University, received funding from the U.S. Office of Naval Research to build a machine that could learn. His machine, the Mark I perceptron, looked like this.

A perceptron is a linear classifier; that is, it is an algorithm that classifies input by separating two categories with a straight line. Input is typically a feature vector x multiplied by weights w and added to a bias b: y = w * x + b.
A perceptron produces a single output based on several real-valued inputs by forming a linear combination using its input weights (and sometimes passing the output through a nonlinear activation function). Here’s how you can write that in math:
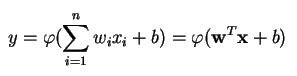
where w denotes the vector of weights, x is the vector of inputs, b is the bias and phi is the non-linear activation function.
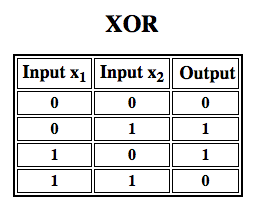
Rosenblatt built a single-layer perceptron. That is, his hardware-algorithm did not include multiple layers, which allow neural networks to model a feature hierarchy. It was, therefore, a shallow neural network, which prevented his perceptron from performing non-linear classification, such as the XOR function (an XOR operator trigger when input exhibits either one trait or another, but not both; it stands for “exclusive OR”), as Minsky and Papert showed in their book.
Apply Reinforcement Learning to Simulations »
Multilayer Perceptrons (MLP)
Subsequent work with multilayer perceptrons has shown that they are capable of approximating an XOR operator as well as many other non-linear functions.
Just as Rosenblatt based the perceptron on a McCulloch-Pitts neuron, conceived in 1943, so too, perceptrons themselves are building blocks that only prove to be useful in such larger functions as multilayer perceptrons.2)
The multilayer perceptron is the hello world of deep learning: a good place to start when you are learning about deep learning.
A multilayer perceptron (MLP) is a deep, artificial neural network. It is composed of more than one perceptron. They are composed of an input layer to receive the signal, an output layer that makes a decision or prediction about the input, and in between those two, an arbitrary number of hidden layers that are the true computational engine of the MLP. MLPs with one hidden layer are capable of approximating any continuous function.
Multilayer perceptrons are often applied to supervised learning problems3: they train on a set of input-output pairs and learn to model the correlation (or dependencies) between those inputs and outputs. Training involves adjusting the parameters, or the weights and biases, of the model in order to minimize error. Backpropagation is used to make those weigh and bias adjustments relative to the error, and the error itself can be measured in a variety of ways, including by root mean squared error (RMSE).
Feedforward networks such as MLPs are like tennis, or ping pong. They are mainly involved in two motions, a constant back and forth. You can think of this ping pong of guesses and answers as a kind of accelerated science, since each guess is a test of what we think we know, and each response is feedback letting us know how wrong we are.
In the forward pass, the signal flow moves from the input layer through the hidden layers to the output layer, and the decision of the output layer is measured against the ground truth labels.
In the backward pass, using backpropagation and the chain rule of calculus, partial derivatives of the error function w.r.t. the various weights and biases are back-propagated through the MLP. That act of differentiation gives us a gradient, or a landscape of error, along which the parameters may be adjusted as they move the MLP one step closer to the error minimum. This can be done with any gradient-based optimisation algorithm such as stochastic gradient descent. The network keeps playing that game of tennis until the error can go no lower. This state is known as convergence.
Footnotes
1) The interesting thing to point out here is that software and hardware exist on a flowchart: software can be expressed as hardware and vice versa. When chips such as FPGAs are programmed, or ASICs are constructed to bake a certain algorithm into silicon, we are simply implementing software one level down to make it work faster. Likewise, what is baked in silicon or wired together with lights and potentiometers, like Rosenblatt’s Mark I, can also be expressed symbolically in code. This is why Alan Kay has said “People who are really serious about software should make their own hardware.” But there’s no free lunch; i.e. what you gain in speed by baking algorithms into silicon, you lose in flexibility, and vice versa. This happens to be a real problem with regards to machine learning, since the algorithms alter themselves through exposure to data. The challenge is to find those parts of the algorithm that remain stable even as parameters change; e.g. the linear algebra operations that are currently processed most quickly by GPUs.
2) Your thoughts may incline towards the next step in ever more complex and also more useful algorithms. We move from one neuron to several, called a layer; we move from one layer to several, called a multilayer perceptron. Can we move from one MLP to several, or do we simply keep piling on layers, as Microsoft did with its ImageNet winner, ResNet, which had more than 150 layers? Or is the right combination of MLPs an ensemble of many algorithms voting in a sort of computational democracy on the best prediction? Or is it embedding one algorithm within another, as we do with graph convolutional networks?
3) They are widely used at Google, which is probably the most sophisticated AI company in the world, for a wide array of tasks, despite the existence of more complex, state-of-the-art methods.
Further Reading
- The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain, Cornell Aeronautical Laboratory, Psychological Review, by Frank Rosenblatt, 1958 (PDF)
- A Logical Calculus of Ideas Immanent in Nervous Activity, W. S. McCulloch & Walter Pitts, 1943
- Perceptrons: An Introduction to Computational Geometry, by Marvin Minsky & Seymour Papert
- Multi-Layer Perceptrons (MLP)
- Hebbian Theory
Other Pathmind Wiki Posts
- Deep Neural Networks
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Attention Mechanisms and Transformers
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Graph Analytics and Deep Learning
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning
Classic Neural Network Papers (pre-2012)
- An analysis of single-layer networks in unsupervised feature learning (2011), A. Coates et al. [pdf]
- Deep sparse rectifier neural networks (2011), X. Glorot et al. [pdf]
- Natural language processing (almost) from scratch (2011), R. Collobert et al. [pdf]
- Recurrent neural network based language model (2010), T. Mikolov et al. [pdf]
- Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion (2010), P. Vincent et al. [pdf]
- Learning mid-level features for recognition (2010), Y. Boureau [pdf]
- A practical guide to training restricted boltzmann machines (2010), G. Hinton [pdf]
- Understanding the difficulty of training deep feedforward neural networks (2010), X. Glorot and Y. Bengio [pdf]
- Why does unsupervised pre-training help deep learning (2010), D. Erhan et al. [pdf]
- Learning deep architectures for AI (2009), Y. Bengio. [pdf]
- Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations (2009), H. Lee et al. [pdf]
- Greedy layer-wise training of deep networks (2007), Y. Bengio et al. [pdf]
- Reducing the dimensionality of data with neural networks, G. Hinton and R. Salakhutdinov. [pdf]
- A fast learning algorithm for deep belief nets (2006), G. Hinton et al. [pdf]
- Gradient-based learning applied to document recognition (1998), Y. LeCun et al. [pdf]
- Long short-term memory (1997), S. Hochreiter and J. Schmidhuber. [pdf]

Chris V. Nicholson
Chris V. Nicholson is a venture partner at Page One Ventures. He previously led Pathmind and Skymind. In a prior life, Chris spent a decade reporting on tech and finance for The New York Times, Businessweek and Bloomberg, among others.