A Beginner's Guide to Bag of Words & TF-IDF
Bag of Words (BoW) is an algorithm that counts how many times a word appears in a document. It’s a tally. Those word counts allow us to compare documents and gauge their similarities for applications like search, document classification and topic modeling. BoW is a also method for preparing text for input in a deep-learning net.
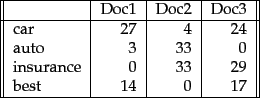
BoW lists words paired with their word counts per document. In the table where the words and documents that effectively become vectors are stored, each row is a word, each column is a document, and each cell is a word count. Each of the documents in the corpus is represented by columns of equal length. Those are wordcount vectors, an output stripped of context.
Before they’re fed to the neural network, each vector of wordcounts is normalized such that all elements of the vector add up to one. Thus, the frequency of each word is effectively converted to represent the probabilities of those words’ occurrence in the document. Probabilities that surpass certain levels will activate nodes in the network and influence the document’s classification.
Learn to build AI in Simulations »
Term Frequency-Inverse Document Frequency (TF-IDF)
Term-frequency-inverse document frequency (TF-IDF) is another way to judge the topic of an article by the words it contains. With TF-IDF, words are given weight – TF-IDF measures relevance, not frequency. That is, wordcounts are replaced with TF-IDF scores across the whole dataset.
First, TF-IDF measures the number of times that words appear in a given document (that’s “term frequency”). But because words such as “and” or “the” appear frequently in all documents, those must be systematically discounted. That’s the inverse-document frequency part. The more documents a word appears in, the less valuable that word is as a signal to differentiate any given document. That’s intended to leave only the frequent AND distinctive words as markers. Each word’s TF-IDF relevance is a normalized data format that also adds up to one.

Those marker words are then fed to the neural net as features in order to determine the topic covered by the document that contains them.
Setting up a BoW looks something like this:
public class BagOfWordsVectorizer extends BaseTextVectorizer {
public BagOfWordsVectorizer(){}
protected BagOfWordsVectorizer(VocabCache cache,
TokenizerFactory tokenizerFactory,
List<String> stopWords,
int minWordFrequency,
DocumentIterator docIter,
SentenceIterator sentenceIterator,
List<String> labels,
InvertedIndex index,
int batchSize,
double sample,
boolean stem,
boolean cleanup) {
super(cache, tokenizerFactory, stopWords, minWordFrequency, docIter, sentenceIterator,
labels,index,batchSize,sample,stem,cleanup);
}
While simple, TF-IDF is incredibly powerful, and has contributed to such ubiquitous and useful tools as Google search. (That said, Google itself has started basing its search on powerful language models like BERT.)
BoW is different from Word2vec, which we cover in a different post. The main difference is that Word2vec produces one vector per word, whereas BoW produces one number (a wordcount). Word2vec is great for digging into documents and identifying content and subsets of content. Its vectors represent each word’s context, the ngrams of which it is a part. BoW is a good, simple method for classifying documents as a whole.

Chris V. Nicholson
Chris V. Nicholson is a venture partner at Page One Ventures. He previously led Pathmind and Skymind. In a prior life, Chris spent a decade reporting on tech and finance for The New York Times, Businessweek and Bloomberg, among others.