A Beginner's Guide to Attention Mechanisms and Memory Networks
I cannot walk through the suburbs in the solitude of the night without thinking that the night pleases us because it suppresses idle details, much like our memory. - Jorge Luis Borges 1
- Vanilla Neural Nets
- Convolutions for Space
- RNNs and LSTMs for Time
- Attention Networks for Words
- Beyond Word Vectors
- Transformer
Attention matters because it has been shown to produce state-of-the-art results in machine translation and other natural language processing tasks, when combined with neural word embeddings, and is one component of breakthrough algorithms such as BERT, GPT-2 and others, which are setting new records in accuracy in NLP. So attention is part of our best effort to date to create real natural-language understanding in machines. If that succeeds, it will have an enormous impact on society and almost every form of business.
One type of network built with attention is called a transformer (explained below). If you understand the transformer, you understand attention. And the best way to understand the transformer is to contrast it with the neural networks that came before. They differ in the way they process input (which in turn contains assumptions about the structure of the data to be processed, assumptions about the world) and automatically recombine that input into relevant features.
Feed-forward networks
Let’s take a feed-forward network, a vanilla neural network like a multilayer perceptron with fully connected layers. A feed forward network treats all input features as unique and independent of one another, discrete.
For example, you might encode data about individuals, and the features you feed to the net could be age, gender, zip code, height, last degree obtained, profession, political affiliation, number of siblings.
With each feature, you can’t automatically infer something about the feature “right next to it”. Proximity doesn’t mean much. Put profession and siblings together, or not.
There is no way to make an assumption leaping from age to gender, or from gender to zip code. Which works fine for demographic data like this, but less fine in cases where there is an underlying, local structure to data.
Convolutional networks
Take images. They are reflections of objects in the world. If I have a purple plastic coffee mug, each atom of the mug is closely associated to the purple plastic atoms right next to it. These are represented in pixels.
So if I see one purple pixel, that vastly increases the likelihood that another purple pixel will be right next to it in several directions. Moreover, my purple plastic coffee mug will take up space in a larger image, and I want to be able to recognize it, but it may not always be in the same part of an image; I.e. in some photos, it may be in the lower left corner, and in other photos, it may be in the center.
A simple feed-forward network encodes features in a way that makes it conclude the mug in the upper left, and the mug in the center of an image, are two very different things, which is inefficient.
Convolutions do something different. With convolutions, we have a moving window of a certain size (think of it like a square magnifying glass), that we pass over the pixels of an image a bit like someone who uses their finger to read a page of a book, left to right, left to right, moving down each time.
Within that moving window, we are looking for local patterns; i.e. sets of pixels next to each other and arranged in certain ways. Dark next to light pixels? That’s an edge! (Try to imagine a moving window used on demographic data: gender next to number of siblings? Means nothing!)
So convolutional networks make proximity matter. And then you stack those layers, you can combine simple visual features like edges into more complex visual features like noses or clavicles to ultimately recognize even more complex objects like humans, kittens and car models.
But guess what, text and language don’t work like that.
Recurrent Networks and LSTMs
How do words work? Well, for one thing, you say them one after another. They are expressed in a two-dimensional line that is somehow related to time. That is, reading a text or singing the lyrics of a song happens one word at a time as the seconds tick by.
Compare that to images for a moment. An image can be glimpsed in its totality in an instant. Most images contain three-dimensional data, at a minimum. If you consider each major color to be its own dimension, and the illusion of depth, then the image contains many more than two. And if you’re dealing with video (or life), you’ve added the dimension of time as well.
One neural network that showed early promise in processing two-dimensional processions of words is called a recurrent neural network (RNN), in particular one of its variants, the Long Short-Term Memory network (LSTM).
RNNs process text like a snow plow going down a road. One direction. All they know is the road they have cleared so far. The road ahead of them is blinding white; i.e. the end of the sentence is totally unclear and gives them no additional information. And the remote past is probably getting a little snowed under already; i.e. if they are dealing with a really long sentence, they have probably already forgotten parts of it.
So RNNs tend to have a lot more information to make good predictions by the time they got to the end of a sentence than they would have at the beginning, because they were carrying more context with them about the next word they wanted to predict. (But some of the context needed to predict that word might be further down a sentence they hadn’t fully plowed yet.) And that makes for bad performance.
RNNs basically understand words they encounter late in the sentence given the words they have encountered earlier. (This is kind of corrected by sending snow plows down the street in two directions with something called bi-directional LSTMS.)
RNNs also have a memory problem. There’s only so much they can remember about long-range dependencies (the words they saw a long time ago that are somehow related to the next word).
That is, RNNs put too much emphasis on words being close to one another, and too much emphasis on upstream context over downstream context.
Attention fixes that.
Attention Mechanisms
Attention takes two sentences, turns them into a matrix where the words of one sentence form the columns, and the words of another sentence form the rows, and then it makes matches, identifying relevant context. This is very useful in machine translation.

So that’s cool, but it gets better.
You don’t just have to use attention to correlate meaning between sentences in two different languages. You can also put the same sentence along the columns and the rows, in order to understand how some parts of that sentence relate to others. For example, where are my pronouns’ antecedents? This is called “self-attention”, although it is so common that many people simple call it attention.
Linking pronouns to antecedents is an old problem, which resulted in this chestnut, mimicking the call and response of a protest march:
WHAT DO WE WANT?
Natural language processing!
WHEN DO WE WANT IT?
Sorry, when do we want what?
A neural network armed with an attention mechanism can actually understand what “it” is referring to. That is, it knows how to disregard the noise and focus on what’s relevant, how to connect two related words that in themselves do not carry markers pointing to the other.
So attention allows you to look at the totality of a sentence, the Gesamtbedeutung as the Germans might say, to make connections between any particular word and its relevant context. This is very different from the small-memory, upstream-focused RNNs, and also quite distinct from the proximity-focused convolutional networks.
Language is this two-dimensional array that somehow manages to express relationships inherent in life over many dimensions (time, space, colors, causation), but it can only do so by creating syntactic bonds among words that are not immediately next to each other in a sentence.
Attention allows you to travel through wormholes of syntax to identify relationships with other words that are far away — all the while ignoring other words that just don’t have much bearing on whatever word you’re trying to make a prediction about (Borges’s “idle details”).
Beyond Word Vectors
Words are social creatures. Like humans, they derive much of their meaning from relationships.
One of the limits of traditional word vectors is that they presume that a word’s meaning is relatively stable across sentences. This is not so. Polysemy abounds, and we must beware of massive differences in meaning for a single word: e.g. lit (an adjective that describes something burning) and lit (an abbreviation for literature) and lit (slang for intoxicated); or get (a verb for obtaining) and get (an animal’s offspring).
While projects like WordNet and algorithms such as sense2vec are admirable attempts to disentangle the meanings of all words in English, there are many shades of meaning for a given word that only emerge due to its situation in a passage and its inter-relations with other words. That is, you can’t even count all the senses of a word in a dictionary. The finest shades of meaning arise in situ.
So we need to expand the domain of inputs that an algorithm considers, and to do that we should include more information about the context of a given word. The charm of linear algebra is that you can calculate many relationships at once; in this case, we are calculating the relationships of each word in a sentence to every other word (self-attention), and expressing those variable relationships that suggest a word’s meaning as a vector. A context vector. It goes beyond word vectors and sense vectors. We have to vectorize all the things. And we can do that with the attention mechanism.
In self-attention, or intra-attention, you might talk about the attention that words pay to each other within a sentence. For any given word, we seek to quantify the context that the sentence supplies, and identify which other words supply the most context with regard to the word in question. The directed arcs of a semantic dependency graph may give you an intuition of how words connect with one another across a crowded sentence, some rising above others to help define certain of their fellows.
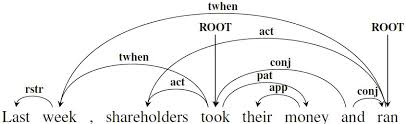
What’s slightly more interesting is how the relationships embodied in a context vector can change our understanding of sentences.
Because sentences are deceptive. Soldiering along under the tyrannies of time and paper, sentences have lulled us into thinking that their meaning is linear, that it unfurls like a ribbon of print across the page. This is not so. In any sentence, some words have strong relationships with other words that are not chockablock next to them. In fact, the strongest relationships binding a given word to the rest of the sentence may be with words quite distant from it.
So it’s probably more fitting to think of sentences folding like proteins in three-dimensional space, with one part of a phrase curling around to touch another part with which it has a particularly strong affiliation, each word a molecule pearling on a polymer.
When we consider sentences as multi-dimensional objects twisting back on themselves, suddenly their ability to map to the obscure and stubborn syntax of real objects in space-time (whose causal relationships, correlations and influences can also be remote, or invisible) seems more intuitive, and it also aligns with certain approaches to neuroscience and the geometry of thought. In fact, attention can help us understand objects’ inter-relations in an image just as well as it aids us with natural-language processing.
Transformer
While attention was initially used in addition to other algorithms, like RNNs or CNNs, it has been found to perform very well on its own. Combined with feed-forward layers, attention units can simply be stacked, to form encoders.
Transformers use attention mechanisms to gather information about the relevant context of a given word, and then encode that context in the vector that represents the word. So in a sense, attention and transformers are about smarter representations.
Feed forward networks treat features as independent (gender, siblings); convolutional networks focus on relative location and proximity; RNNs and LSTMs have memory limitations and tend to read in one direction. In contrast to these, attention and the transformer can grab context about a word from distant parts of a sentence, both earlier and later than the word appears, in order to encode information to help us understand the word and its role in the system called a sentence.
There are various architectures for transformers. One of them uses key-value stores and a form of memory.
To quote Hassabis et al:
While attention is typically thought of as an orienting mechanism for perception, its “spotlight” can also be focused internally, toward the contents of memory. This idea, a recent focus in neuroscience studies (Summerfield et al., 2006), has also inspired work in AI. In some architectures, attentional mechanisms have been used to select information to be read out from the internal memory of the network. This has helped provide recent successes in machine translation (Bahdanau et al., 2014) and led to important advances on memory and reasoning tasks (Graves et al., 2016). These architectures offer a novel implementation of content-addressable retrieval, which was itself a concept originally introduced to AI from neuroscience (Hopfield, 1982).
In this architecture, you have a key, a value, and a search query. The query searches over the keys of all words that might supply context for it. Those keys are related to values that encode more meaning about the key word. Any given word can have multiple meanings and relate to other words in different ways, you can have more than one query-key-value complex attached to it. That’s “multi-headed attention.”
One thing to keep in mind is that the relation of queries to keys and keys to values is differentiable. That is, an attention mechanism can learn to reshape the relationship between a search word and the words providing context as the network learns.
Further Resources
- Transformer: A Novel Neural Network Architecture for Language Understanding
- The Illustrated Transformer
- The Annotated Transformer
- AlphaStar: Mastering the Real-Time Strategy Game StarCraft II(Contains a transformer)
- Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing
- VIDEO: Successes and Challenges in Neural Models for Speech and Language - Michael Collins
- VIDEO: Comparing Attention with convolutional networks and recurrent nets
- From Attention in Transformers to Dynamic Routing in Capsule Nets
- Neuroscience-Inspired Artificial Intelligence, by Demis Hassabis et al
- Transformers are Graph Neural Networks
- GPT-3: Language Models are Few-Shot Learners
- GPT-3: Learning to Summarize with Human Feedback
Other Reading
- Deep Neural Networks
- Graph Analytics and Deep Learning
- Recurrent Neural Networks (RNNs) and LSTMs
- Word2vec and Neural Word Embeddings
- Convolutional Neural Networks (CNNs) and Image Processing
- Accuracy, Precision and Recall
- Eigenvectors, Eigenvalues, PCA, Covariance and Entropy
- Symbolic Reasoning and Machine Learning
- Markov Chain Monte Carlo, AI and Markov Blankets
- Deep Reinforcement Learning
- Generative Adversarial Networks (GANs)
- AI vs Machine Learning vs Deep Learning
- Multilayer Perceptrons (MLPs)
- Simulation, AI and Optimization
Until recently, most CNN models worked directly on entire images or video frames, with equal priority given to all image pixels at the earliest stage of processing. The primate visual system works differently. Rather than processing all input in parallel, visual attention shifts strategically among locations and objects, centering processing resources and representational coordinates on a series of regions in turn (Koch and Ullman, 1985, Moore and Zirnsak, 2017, Posner and Petersen, 1990). Detailed neurocomputational models have shown how this piecemeal approach benefits behavior, by prioritizing and isolating the information that is relevant at any given moment (Olshausen et al., 1993, Salinas and Abbott, 1997). As such, attentional mechanisms have been a source of inspiration for AI architectures that take “glimpses” of the input image at each step, update internal state representations, and then select the next location to sample (Larochelle and Hinton, 2010, Mnih et al., 2014) (Figure 1A). One such network was able to use this selective attentional mechanism to ignore irrelevant objects in a scene, allowing it to perform well in challenging object classification tasks in the presence of clutter (Mnih et al., 2014). Further, the attentional mechanism allowed the computational cost (e.g., number of network parameters) to scale favorably with the size of the input image. Extensions of this approach were subsequently shown to produce impressive performance at difficult multi-object recognition tasks, outperforming conventional CNNs that process the entirety of the image, both in terms of accuracy and computational efficiency (Ba et al., 2015), as well as enhancing image-to-caption generation (Xu et al., 2015).
1) No puedo caminar por los arrabales en la soledad de la noche, sin pensar que ésta nos agrada porque suprime los ociosos detalles, como el recuerdo.

Chris V. Nicholson
Chris V. Nicholson is a venture partner at Page One Ventures. He previously led Pathmind and Skymind. In a prior life, Chris spent a decade reporting on tech and finance for The New York Times, Businessweek and Bloomberg, among others.